《机器学习有意思! 01》- 世界上最简单的机器学习入门
《机器学习有意思! 01》- 世界上最简单的机器学习入门
原文:Machine Learning is Fun! Part 1 —— The world’s easiest introduction to Machine Learning
作者:Adam Geitgey
你是否也曾听人们谈起机器学习但是只有一个朦胧的概念?你是否厌倦了在同事的高谈阔论中颓然欲睡?此诚求变之机。
本教程适合所有对机器学习感到好奇,却不知从何下手的读者。我想应该有很多人试着读了维基百科页面,然后愈发迷惘、沉沦,盼望着有人能够提供一个high-level的解释,那你找对地方了。
我们的目标是让所有人都能读懂——这就难免有些泛泛而谈。但是无妨,但凡本文能让一个人真正对机器学习感兴趣,那么目的就算达到了。
什么是机器学习?
机器学习的核心思想是创造一种普适的算法,它能从数据中挖掘出有趣的东西,而不需要针对某个问题去写代码。你需要做的只是把数据“投喂”给普适算法,然后它会在数据上建立自己的逻辑。
比如说有一种算法,叫分类算法,它可以把数据分到不同的组别当中。一个识别手写数字的分类算法,也可以用作判断垃圾邮件,而无需修改一行代码。算法是同一个算法,只是输入了不同的训练数据,便有了不同的分类逻辑。
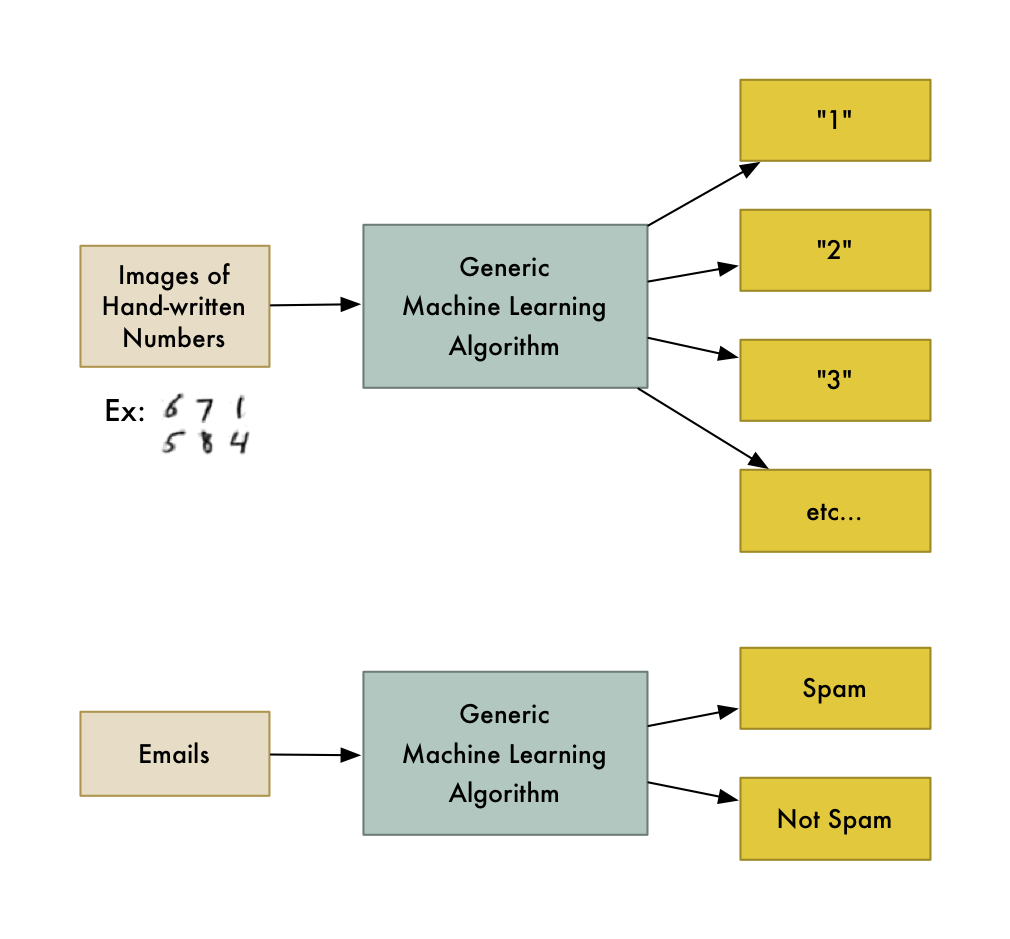
机器学习算法是个黑盒,且可以在不同分类问题中重复利用。
“机器学习”是个筐,什么普适算法都往里装。
两种机器学习算法
机器学习主要分为两类——有监督学习和无监督学习,区别很简单,却很关键。
有监督学习
想想你是一家房产中介。你的业务正在增长,所以雇了一帮实习销售来助拳。那么问题来了——身经百战的你,一眼就看穿一栋房子价值几何,但是实习生可没有这样丰富的人生经验,所以摸不准行情。
为了辅助实习生(以便解放自己度个假),你决定做个小程序,基于面积、周边环境、相似房产成交价等等,来预估本地的房价。
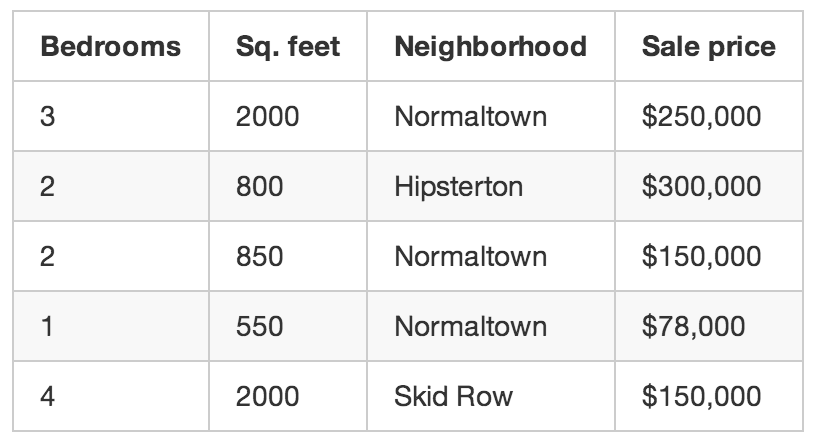
所以你把3个月来本市的每一笔交易都拿小本本记了下来。对每处房产都整理了一大堆细节——房间数、面积、周边环境等等,当然最重要的是,最终成交价:

这就是我们的“训练数据”
有了训练数据,我们就想搞个程序去预估其他的房价:
用训练数据去预测别的房屋价格
这就是有监督学习。你是知道每处房产到底卖多少的,换言之,问题的答案是已知的,逻辑是可以反推的。
为了开发小程序,把每处房产的训练数据导进机器学习算法里,算法试图摸索出其中的数学规律。
这有点像是去掉了符号的算术题答案:
无监督学习Oh no!一个熊孩子把参考答案里的运算符号给涂没了!
根据上图,你能否推算出这些题目的原貌呢?显然,我们需要对这些数字“动点手脚”,以使等式成立。
在有监督学习中,我们做的实际上就是让电脑代替人来让等式成立。一旦你学会了解决某一类问题,那么这类问题里的任何子问题都就迎刃而解了!
无监督学习
回到最开始那个卖房地产的例子。如果我们不知道具体每处房产的价格可咋整?即使仅知道面积、位置等信息,你也依然可以搞点动静出来,这就叫无监督学习。
即使不预测未知数(比如房价),机器学习也能带来有趣的结论
这就好比有人给你一张纸,上面写着一串数字,然后说“我也不知道啥意思,你可以猜猜这是什么套路——好运!”
这些数据我们能做什么呢?对于新手来讲,可以得到一个算法—,从数据中自动辨识出细分的市场定位。可能你会发现,当地大学附近的购房者偏好多卧室的小房子,而郊区的购房者则倾向于大套三。了解到不同类型消费者的存在可以指导市场行为。
另一个可以做的就是自动识别出那些少有相似点的特异房产。可能这些特异房产是豪华公馆,那么就可以调配最好的销售人员专门负责这些大买卖。
后文主要专注于有监督学习,但并非因为无监督学习的作用小或者趣味少。实际上无监督学习的重要性与日俱增且发展迅速,因为不需要事先对正确答案对应的数据加标签。
注:还有很多其他种类的机器学习算法,不过建议从这些基础算法入手。

 无监督学习
无监督学习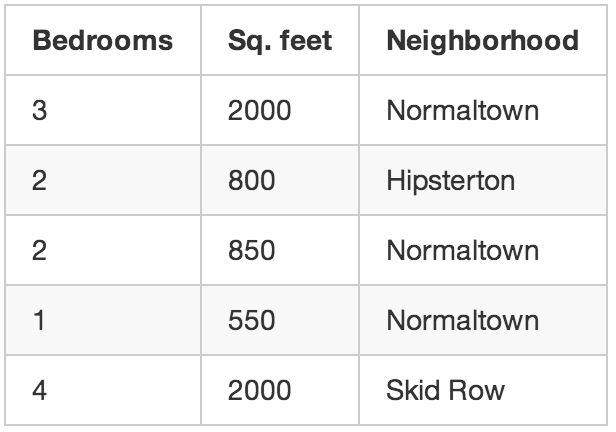
哎哟不错,但是真的有可能“学习”到真实的房价吗?
作为一个人类,你的大脑可以面对各种形势,并且在无明确指导的情况下自主学习如何应对。如果你卖了很久的房子,就会慢慢地对房价、对销售策略、对观察客户等问题产生一种“感觉”。强人工智能研究的目的就在于让计算机掌握这种能力。
但是当前的机器学习算法还没那么厉害——它们只能对很具体、有限的问题生效。或许这里的“学习”更应该定义为“基于样本数据得出解决具体问题的等式”。
不幸的是,“让机器基于样本数据得出解决具体问题的等式”不是个好名字,所以我们还是回到了“机器学习”。
当然如果你在50年后,强人工智能都普及了时候看到本文,会觉得全文都很“古典”。别看了,让你的机器人给你拿个包子吃,未来人类。
放码过来!
然,上面例子里的预测房价程序应该怎么写呢?思考一秒,然后接着看。
如果你对机器学习一无所知,可能会尝试依照预测房价的基本规律,写出如下代码:
1 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): |
如果顺着写上几个小时,或许也能得到一个能跑的程序。但势必存在隐患,而且无法应对价格变化。
如果计算机能自己发现如何应用这些方程,那岂不是好得多?只要能得到正确的数字,谁管具体方程是什么呢?
1 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): |
这个问题可以想象成:价格是道炖菜,配方是卧室数量,面积和周边环境。如果你能算出每种成分对最终价格的影响是多少,或许那就是配方“搅合”最终价格的确切权重。
这可以使原程序(满是if/else)变得简单如下:
1 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): |
注意这些奇妙深刻的加粗数字——**.841231951398213、 1231.1231231、2.3242341421和201.23432095,这就是我们的权重**。只要我们能找到准确的权重,那就可以预测房价了。
一个比较粗暴的权重计算方法大致如下:
第一步
把所有权重都设为1.0:
1 | def estimate_house_sales_price(num_of_bedrooms, sqft, neighborhood): |
第二步
把每个房产的参数代入公式,计算预测结果和实际价格的误差:
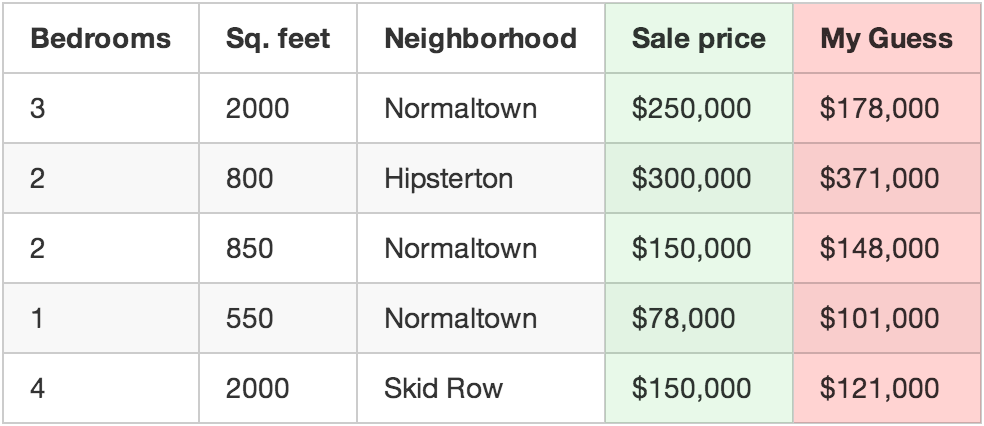
用你的方程来猜房价
比如第一个房子实际卖了250,000,但是你的方程却预测的是178,000,但这一个房子就少了72,000。
现在把每个房子对应误差的平方加起来,比方你有500单交易,那么误差的平方和就有$86,123,373,可谓谬以千里。再把平方和除以500得到平均每个房子的误差,这一平均误差值就是方程的代价(即最小二乘法,平方是为了防止误差正负相抵)。
如果我们能通过调整权重将代价降为零,那方程就完美了。这表示在所有例子中,方程都准确无误地基于输入数据猜中了房价。这就是我们的目标——尝试不同的权重,让代价尽量低。
第3步:
不断地重复第2步,尝试每一种可能的权重值组合。哪个组合能让代价最接近于0就选哪一组。找到那一组权重,就解决了问题!
脑洞时间
挺简单的对吧?回想一下刚才的所做,拿到一些数据,填进三个普适的、简单的步骤里,然后得到一个能猜房价的方程。Zillow(美国房价预测网站)面临着严重的威胁!
但是有这么几个激动人心的事实:
过去40年里,很多领域(如语言学/翻译学)的研究已经表明,“搅合数字炖菜”(作者自己打的比方)的普适性学习算法已经超越了那些,由真人尝试自己发现显式规律的人方法。机器学习的“暴力”方法最终击败了人类专家。
刚才得出的方程其实是很笨的。它并不知道“平方米”和“卧室”到底是什么,它只知道“搅拌”多少数字可以得到正确答案。
你大概并不知道为什么某一组权重就是好的,而只是写了一个自己都不明白的方程,但却证明是好用的。
假设我们不用“平方米”和”卧室数“这些参数,而是读入一个数列。比方说每个数字代表的是”从车顶上拍的照片的某一像素的亮度”,然后我们预测的结果也不是“房价”了,而是“方向盘转过的角度”。这就是一个人自动驾驶的风方程了?
疯了,对吧?
第3步的“尝试每个数字”
当然你不可能真的尝试每一种可能权重组合来寻找最优解,实际情况是永远尝试不完。
为了避免这一情况,数学家们发现了很多机智办法来尽快找到一个不错的结果。以下就是其中一种:
第一,写一个能够代表上面“第2步”的方程:
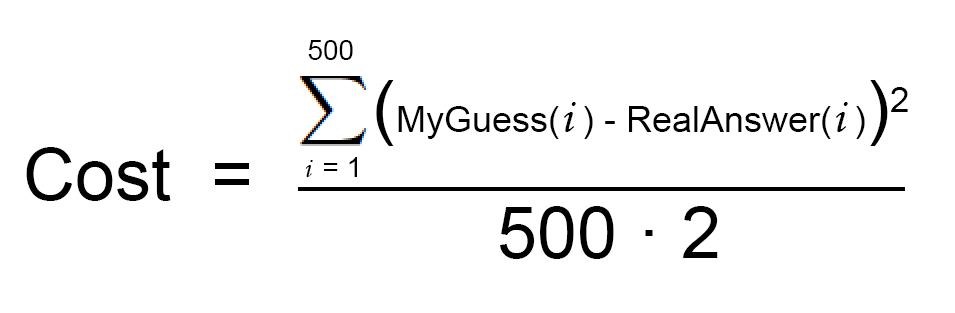
这就是代价函数
然后用机器学习界的黑话(暂时可以忽略)重新写一遍:
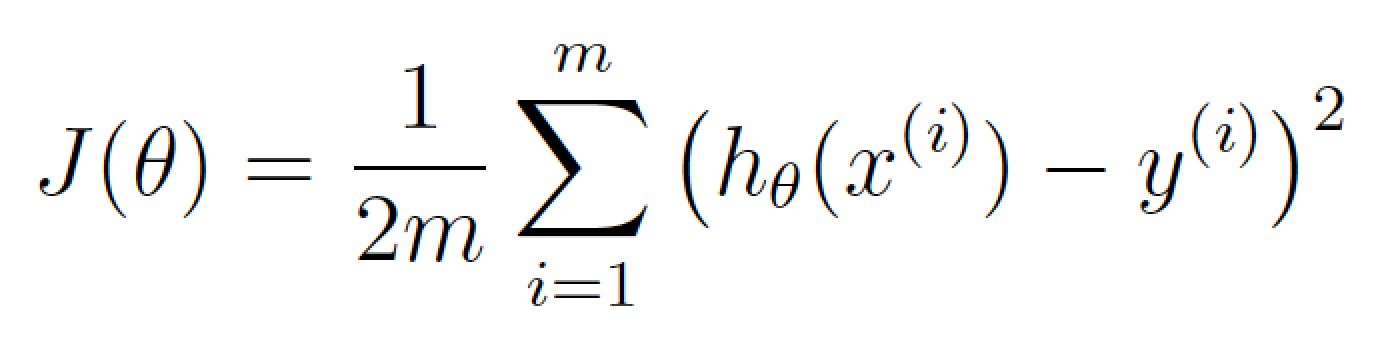
θ代表当前权重。J(θ)是当前权重的代价值。
这个等式代表了在当前的权重组合下,我们的价格预测有多么离谱。
如果把房间数和平方米所有可能权重值可视化,可以得到类似下图的图像:
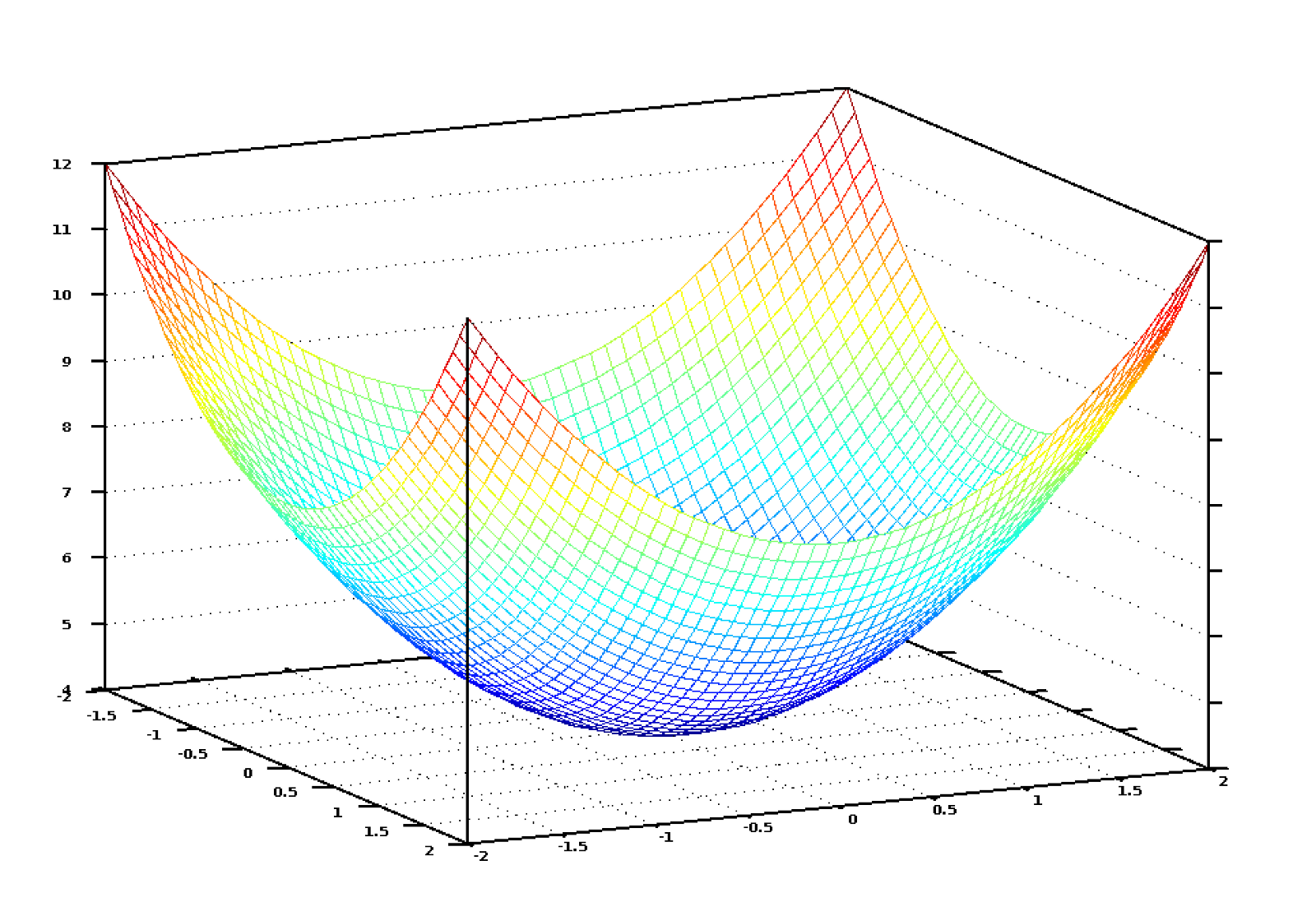
代价函数的图像像个碗。竖直轴表示代价。
这个图里的蓝色最低点就是代价的最低点——方程误差最小处,最高点即是最离谱的情况。所以如果我们找到一组权重值,使得方程对应最低点,那就是答案!
所以我们只需要以“下山”的方式来调整权重,逼近最低点。如果每一次微小的调整都向着最低点进发,那迟早能够到达。
函数的导数就是切线的斜率,换句话说,这告诉我们哪条路可以“下山”。
因此如果计算代价函数对每个权重的偏微分,然后再从权重里减去这个值,这可以让我们离谷底更近。重复执行,最终我们会到达谷底并获得权重的最优解(如果没看懂,不要担心,继续看)。
这是一种寻找方程最佳权重方式的高度概括,叫作批梯度下降(batch gradient descent)。如果你对此感兴趣,不要害怕,了解更多细节。
当你使用机器学习库来解决实际问题的时候,这些都会自动完成,但是了解究竟发生了什么还是很有用的。
还略过了什么?
上述的三步算法即是多变量线性回归,针对一条穿过房产数据的直线来进行预测目标等式,并用这一等式去猜测此前未曾见过的房屋价格,解决实际问题的时候这非常行之有效。
但是以上方法或许只对特别简单的例子好使,并非万金油。其中一个原因就是房价不总是简单到能用一条连续直线来代表。
好在另有很多方法解决,很多机器学习算法可以处理非线性数据(如神经网络 或 有核 的支持向量机)。同样也有算法是以更加聪明的方式使用线性回归以拟合更复杂的直线。但不论哪一方法,最根本的思想都是找到最佳的权重。
并且我忽略了过拟合问题。对于已有的原始数据,找到一组很棒的权重值不难,但是却有可能对训练集以外新的房子不适用。有很多方法可以避免这一现象(如正则化和使用交叉验证数据集),这是成功应用机器学习算法的关键命题。
尽管基本概念很简单,但是要用机器学习取得有用的结果,还是需要技巧和经验的。不过这些技巧是每一个开发者,都能够学会的!
机器学习是魔法吗?
看到机器学习技术如此轻易就解决了看起来非常困难的问题(如手写识别),你可能会感觉只要有足够多的数据,什么问题都不是问题了。导入数据,然后等着计算机变出一个适合数据的式子!
但需要记住的事,机器学习要想生效,必须满足一个条件,就是目标问题对已有数据确实是可解的。
比如建立一个模型,根据房子里种的植物种类预测房价,这肯定不管用。因为房里的植物和售价本来就没有关系,不管再怎么试,计算机还是无法找出这种关系。
只有实际存在的关系才能建模
所以如果一位人类专家不能用数据解决某个问题,计算机也不行。相反,计算机的优势在于,对于人类能解决的问题,计算机可以更快地完成。
如何学习更多机器学习
在我看来,机器学习目前最大的问题在于其主要还是存在于学术界,对于广大只是想稍微了解、而并非想成为专家的人们,通俗易懂的材料还是不够丰富,当然这一情况已经在好转。
吴恩达的Machine Learning class on Coursera相当惊艳,我强烈推荐从这里开始。对于CS专业的人,只要还记得一丁点数学,就可以学。
你也可以通过下载安装Scikit-learn,来自己尝试海量的机器学习算法,这是一个提供“黑盒”版标准算法的Python框架。
- 微信
- 支付宝


